用 Rust 重写 MDX 编译
@mdxor/compiler 是一个用 Rust 编写、高速并且零依赖的 MDX 解析器。 我刚刚完成它的绝大部分功能,这里分享一下它的实际效果和实现原理
Benchmark
为了测试其在前端领域的性能,我不仅将 @mdxor/compiler 通过 Napi-rs 封装成 Node.js native addon, 还把 @mdxor/compiler
编译成 wasm,以分别测试其在 Node.js 和浏览器上的速度
以下是测试结果(仅供参考,Benchmark 代码):
MacBook Pro (13-inch, 2017)8 GB
Mdxor Napi x 15,963 ops/sec ±1.16% (91 runs sampled)
Official Mdx Node.js x 225 ops/sec ±5.25% (83 runs sampled)
Mdxor Wasm x 8,181 ops/sec ±7.06% (46 runs sampled)
Official Mdx Browser x 125 ops/sec ±23.35% (44 runs sampled)不论是从文字表述还是可视化图表,都可以看出在该项测试中 @mdxor/compiler 的速度大幅领先官方的 @mdx-js/mdx。
其中,Node.js 上的速度约为官方的 70 倍,浏览器上则约为 65 倍
实现原理
MDX 介绍
MDX 是一个结合了 Markdown 和 JSX 的文档格式。 它在 Markdown 简洁的标准文档格式基础上,结合 JSX 的灵活 & 组件化,让文档内容更加丰富
以下是一个简单的 MDX 文档:
import Chart from './chart'
# Title
This is a chart
<Chart />可以看出,MDX 主要由头部的 import 和 export、GitHub Flavored Markdown 以及穿插在其中的 JSX 组成。
接下来的篇幅我会解释 @mdxor/compiler 如何解析一个 MDX 文档
JSX/JS 部分
对于头部的 import/export(JS) 和文档中的 JSX,我写了一套简单的 JS/JSX 解析器,用以验证语法的正确性。
如果不符合 JS/JSX 规范,会将它以文本的格式输出
官方 @mdx-js/mdx 使用 acornjs 解析 JSX/JS,所以支持所有 JS 语法。
但是 MDX 只有头部 import/export 和 JSX 标签中会存在 JSX/JS 语法,需要的特性有限。
针对 MDX 中 JS/JSX 的语法特性,@mdxor/compiler选择性地支持一些常用的 JS/JSX 语法,如下:
| 语法 | 例子 |
|---|---|
| 基础数据类型 | true, null, undefined, 100, "str" |
| 引用数据类型 | [], {}, {a:[true, {b:"str"}]} |
| 变量成员 | a.b, a[b], a['b'] |
| 函数调用 | a(), a(1, true, "s") |
| 三元运算 | a ? b : c |
| 数学运算 | a + b, a += 1 |
| 逻辑运算 | a && b, !!a, a == b |
| export | export const a = 10, export React from "react" |
| import | import React, {useState} from "react" |
| jsx | <Comp1 props={["true"]}><Comp2 /></Comp1> |
| 模版字符串 | `12`, `12${a}` |
这些语法均可相互嵌套,比如以下:
export const a = { b: ['str'], c: <div test={true}></div> }一开始,我准备直接调用 SWC 做这部分工作,但由于它的 Rust 库并没有暴露单独解析 import/export 的方法,最后我决定手写这部分代码。
虽然目前支持的语法不算全面,但经过测试,这部分不太影响解析速度,并且自有词法分析、语法分析,易拓展,后续可以再逐渐补全
词法分析
词法分析是将语句转为单词(Token)的过程,在 @mdxor/compiler 中定义了几种 Token 类型:
pub enum JSToken {
Keyword(Span), // 关键字
Punctuator(Span), // 符号
String(Span), // 字符串
Template(Span), // 模版字符串
Identifier(Span), // 标识符
Number(Span), // 数字
Text(Span), // JSX 中的文本
}export let a = { b: true } 这段语句最后会被转化为 export 关键字, let 关键字, a 标识符, = 符号, { 符号, b 标识符, : 符号, true 关键字, } 符号
语法分析
语法分析是在词法分析的基础上将单词序列组合成合法的语句
比如 export 关键字 后跟 let 关键字,程序会继续执行,其后又跟了一个 var 关键字,语法分析就会失败
Markdown 部分
Markdown 的解析主要遵从 GitHub Flavored Markdown 提到的解析策略
Markdown 由 Block 块(标题、段落、表格等) 和 Inline 内联(强调、链接等) 组成
Block
Block 又分为两种,一种是可以包含其他 Block 的,称之为 Container Block,另一种则不能包含其他 Block,称之为 Leaf Block
由于 Container Block 可以不停地嵌套,在解析时,需要重复扫描 Block,直至 Block 为 Leaf Blcok,再读取该 Leaf Block 的内联内容(这里不对内联解析)
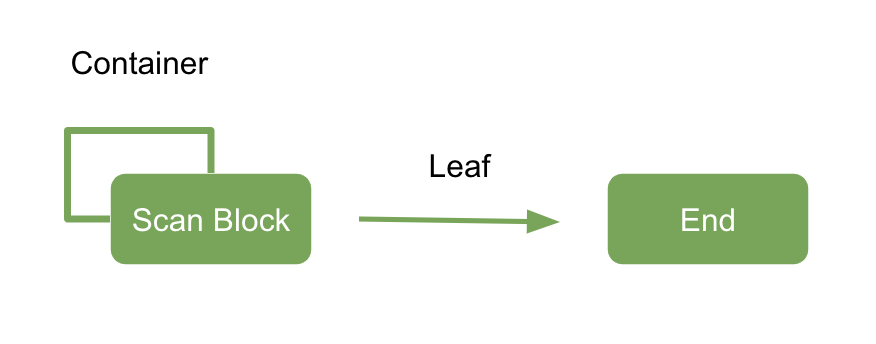
这里还有一个难点,即是处理 Container Block 的连续性:
- 123
# title在以上 Markdown 中,# title 是隶属于 List 的 Item 的。但 Markdown 是空格敏感的,如果删除了# title前面的空格,# title将直接隶属于文档的根元素,所以我们在解析新一行的时候,需要先判断出它的父元素
因为由于链接引用的存在,所以会存在 Inline 链接 引用的是之后出现的链接定义(可以类比为 JS 中的变量提升)。所以解析完整个文档的 Block 后,我们才解析各 Leaf Block 的内联元素
Inline
内联部分的解析比较简单,需要注意的是各内联元素的优先级
*a`a*a`在上面这段 Markdown,即使是 *(强调) 符号最先开始,并且也最先闭合,但仍是将 a*a 解析为内联代码,*a 解析为文本
最后
截止目前, @mdxor/compiler 仍需要补全一些功能并进行完备的测试,还无法在生产环境使用,所以暂未发布在 npm 上。
可以移步至 @mdxor/compiler 仓库 查看它的最新动态